Overview
This is an overview of the BLOOCK's Protocol and its technological stack. It's objective is to provide an introduction for developers to BLOOCK's technical stack. It also offers the approach to achieve high scalability. The explanation assumes you are familiar with the Ethereum ecosystem, the basic concepts of cryptography, and structures such as hashing and Merkle trees.
First approach
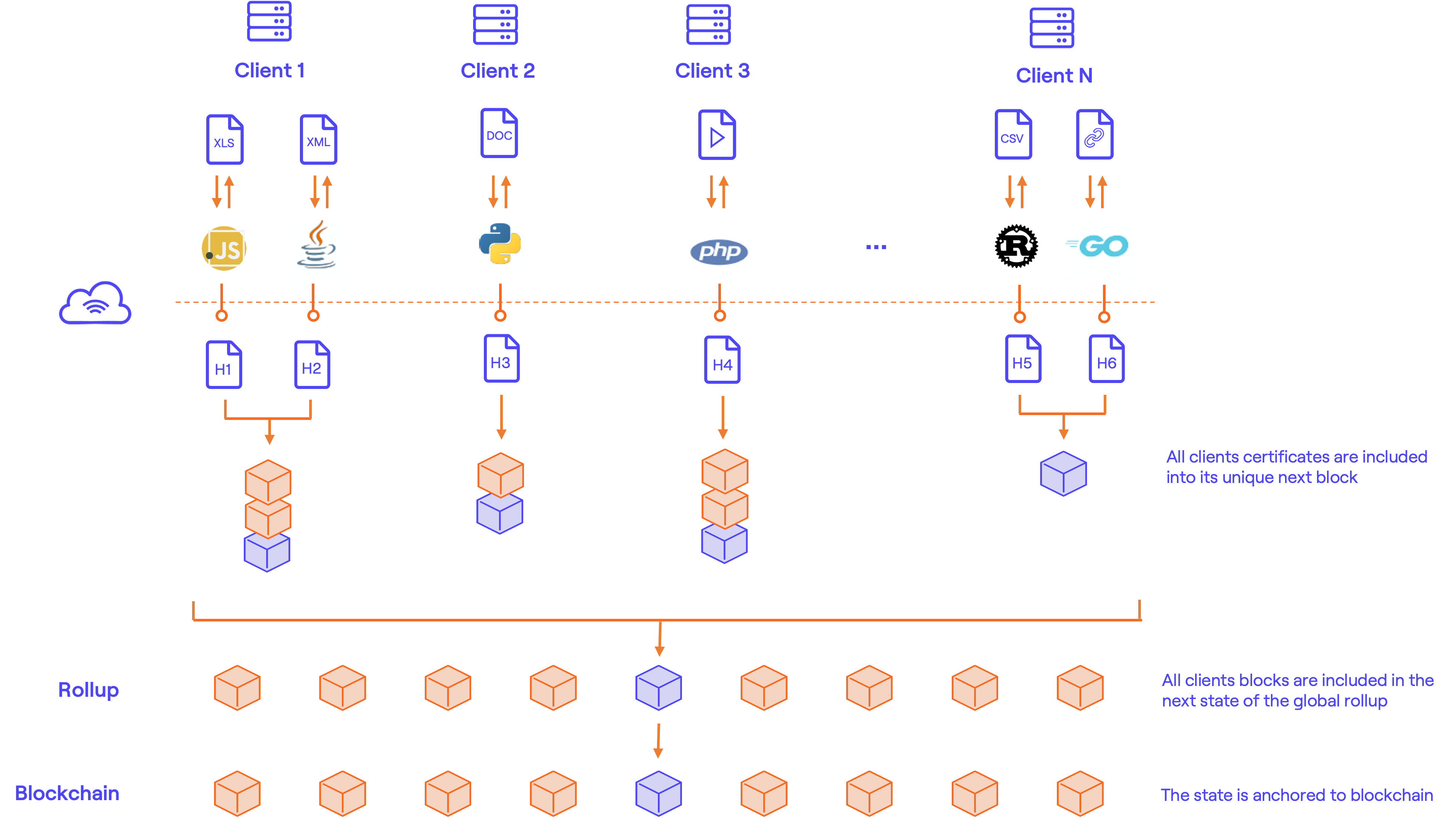
BLOOCK is a rollup solution that allows scaling data-tamper proofing on top of permissionless blockchain technologies. It uses blockchains for state storage but not for the computation of the aggregations, which is made internally with a specific frequency that depends on the network it is anchored to. The basic architecture of BLOOCK is simplified to ease understanding:
Protocol
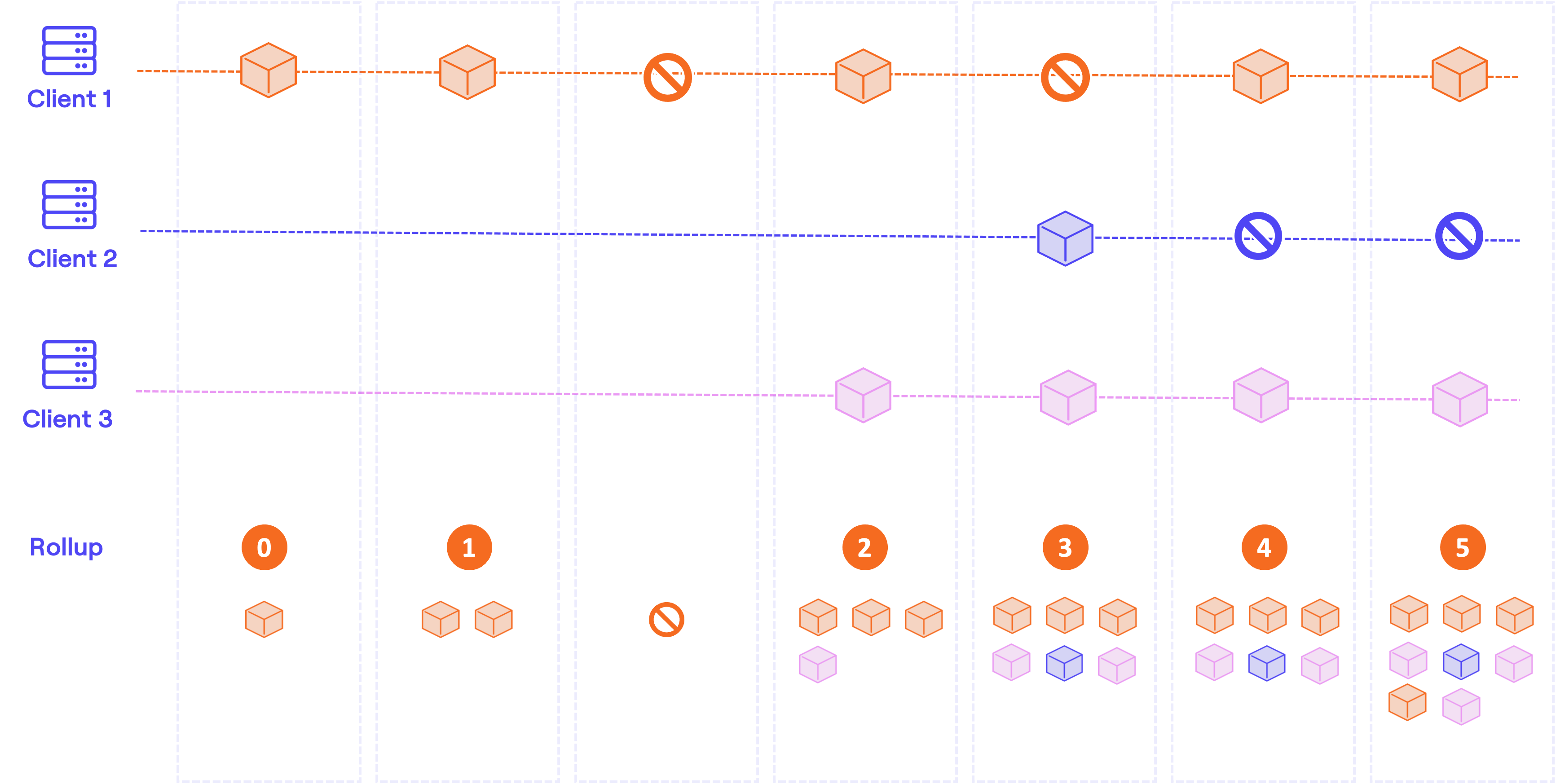
BLOOCK manages an internal protocol that aggregates and consolidates messages to the L2 rollup with a certain time frequency. The messages received are queued internally between anchors in a pool of pending certificates. When the anchoring mechanism is executed, all the pending messages of the pool are included in the state chain of each client. A state chain is client independent and each client owns its chain of states. A genesis random hash forms the first block of each client state chain along with a set of certifications sent since the last confirmed anchor. From there on, the last client block root represents each block and all the certifications sent since the last confirmed anchor. Some may be wondering why is it necessary to separate each client message into independent shards. Mainly because of the following crucial points:
- Sync size: If no separation was made, any client synced with the whole BLOOCK State would have to download all certificates included by all clients to the state tree. This will lead to the storage of lots of unnecessary data. With this approach, only 1 chain root per client needs to be stored for each anchor to regenerate the BLOOCK State fully.
- Repeated certificates: If all certificates were stored in a single Rollup State, repetitions wouldn't be included in the blockchain. They would already be present in previous states. By adding them by blocks chained one to another, all repetitions will be stored in different state root anchors.
- Right to be forgotten: Any client in need to remove all certifications from BLOOCK State will be allowed to do so. BLOOCK will just keep the root of each of its blocks in the Rollup, which indeed has 0 links to the certifications sent thanks to the first block genesis hash.
Once all client messages have been included in their respective state chains, the root of each new block created is appended to the BLOOCK Rollup stored by an only-append binary sparse Merkle tree. Once this action is finalized, we can conclude that all pending messages have been incorporated into the state of BLOOCK. Since we have a single shared state tree, BLOOCK can provide proofs that concatenate multiple certificates efficiently.
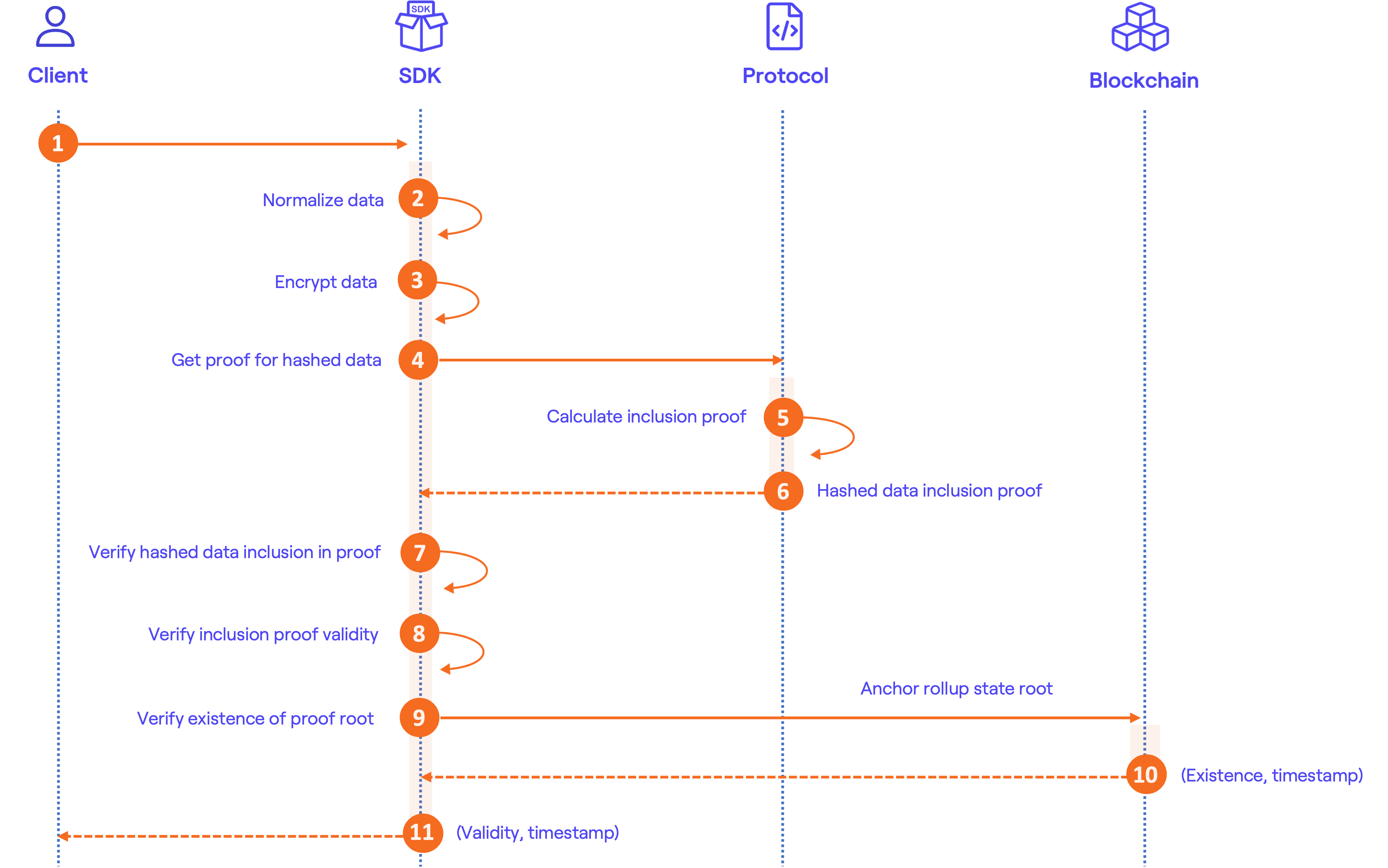
Certification flow
To certify data with BLOOCK, the process involves several steps, some of which require implementation on your end using our SDKs, while others are handled by BLOOCK itself. Below is a summary of the certification flow:
- Prepare data:
- Send data
- Synchronization
Here's a diagram of the certification process:
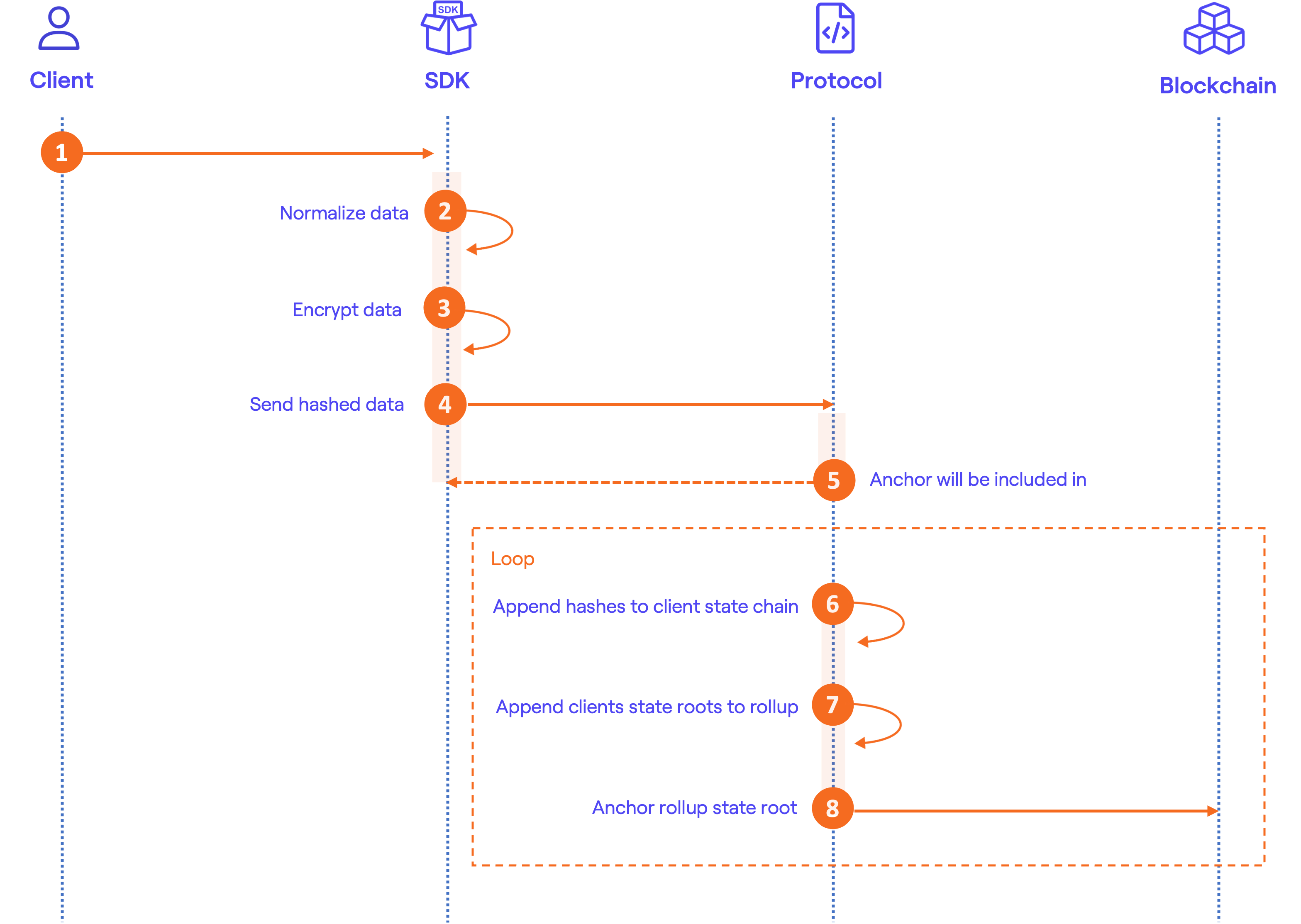
Validation flow
For the validation flow, verifying the authenticity and integrity of certified data involves a series of steps. These steps are detailed in the verification section of our documentation and can be implemented using examples provided. Additionally, we offer ready-to-use tools in the Validators section for those who prefer a more streamlined approach.
Here's a diagram of the verification process: